HunyuanOCR от Tencent: мультимодальное распознавание текста нового поколения
Введение
Китайский технологический гигант Tencent выпустил новую ИИ-модель HunyuanOCR — решение следующего поколения в области мультимодального распознавания текста. Разработчики позиционируют её как инструмент, кардинально меняющий представления о том, каким должно быть OCR-решение в эпоху больших языковых моделей. Несмотря на относительно скромный объём — всего 1 миллиард параметров — система уже демонстрирует производительность, сопоставимую с ведущими отраслевыми моделями, оставаясь при этом компактной и удобной в развёртывании. В этом материале редакция СервакМастер подробно разбирает возможности и архитектурные особенности HunyuanOCR.
Что такое HunyuanOCR и чем она отличается от конкурентов
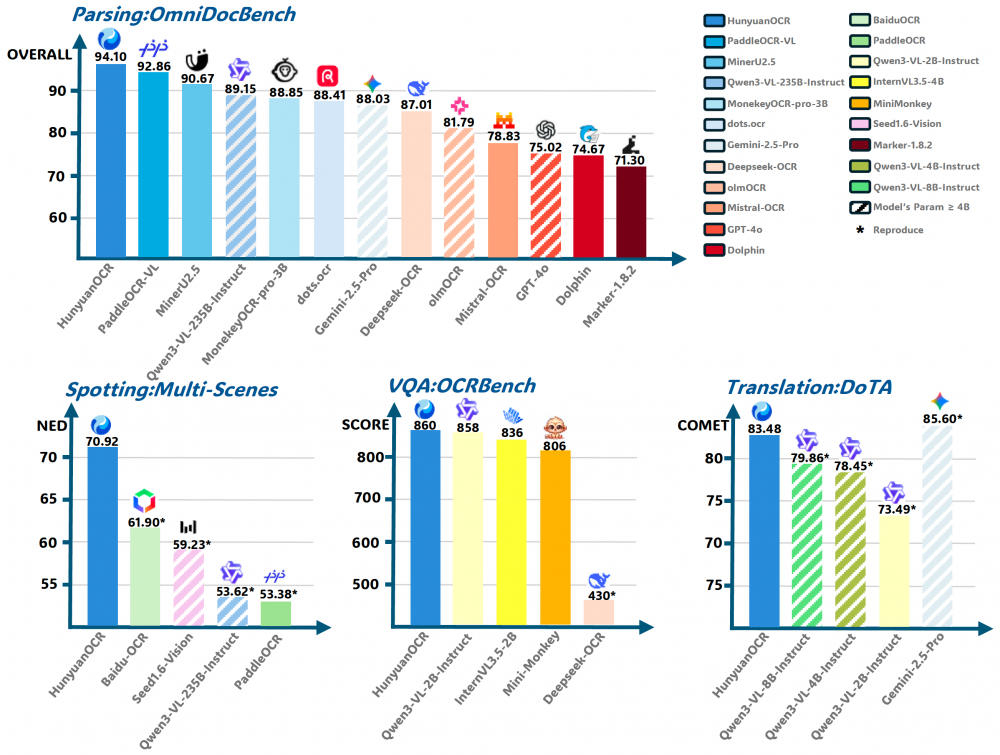
HunyuanOCR строится на мультимодальной архитектуре с оптимизированной стратегией обучения. Именно это сочетание позволяет модели работать на уровне значительно более крупных OCR-систем при существенно меньших вычислительных затратах. По результатам тестирования Tencent, HunyuanOCR уже опережает такие популярные решения, как:
- PaddleOCR-VL — широко используемая открытая OCR-система;
- Qwen3-VL-235b — мощная мультимодальная модель Alibaba;
- Gemini-2.5 Pro — флагманская мультимодальная модель Google;
- DeepSeek-OCR — OCR-решение от китайского стартапа DeepSeek.
Такое превосходство над конкурентами при объёме в 1 млрд параметров — весомый аргумент в пользу эффективности архитектурных решений, заложенных командой Tencent.
Функциональные возможности модели
HunyuanOCR охватывает широкий спектр задач, связанных с анализом и обработкой текста:
- Обнаружение и распознавание текста — классические OCR-задачи, с которыми модель справляется с высокой точностью;
- Сложный структурный анализ документов — распознавание таблиц, форм, вложенных блоков и нестандартных макетов;
- Открытое извлечение информации — семантический разбор содержимого документа по запросу пользователя;
- Работа с субтитрами видео — извлечение и обработка текста из видеоматериалов;
- Перевод текста с изображений — распознавание текста с одновременным переводом на нужный язык;
- Проверка качества документа — автоматическая оценка читаемости и структурной корректности.
Принципиальное отличие HunyuanOCR от классических каскадных систем заключается в сквозном (end-to-end) подходе к обработке. В традиционных решениях распознавание документа требует последовательного запуска множества отдельных ИИ-модулей: детектора, классификатора, транскрибера, постпроцессора. HunyuanOCR выполняет всё это в рамках одной инструкции: пользователь формулирует задачу — модель возвращает готовый результат. Это кардинально сокращает время обработки и снижает сложность интеграции в production-среды.
Многоязычная поддержка
Одним из ключевых достижений HunyuanOCR является полноценная поддержка более ста языков. Модель уверенно распознаёт и анализирует тексты в самых разнообразных языковых системах, включая сценарии, где в рамках одного документа одновременно присутствуют несколько языков или алфавитов. Это особенно актуально для:
- международного документооборота в глобальных компаниях;
- платформ, работающих с мультиязычными пользовательскими данными;
- приложений для обработки иностранных сканов и архивных материалов;
- систем автоматического перевода документов в режиме реального времени.
Широкая языковая поддержка в сочетании с высокой точностью делает HunyuanOCR конкурентоспособным выбором для международного рынка.
Требования к инфраструктуре для развёртывания
Для корректной работы модели разработчики Tencent определили следующую стандартную среду развёртывания:
| Компонент | Требование |
|---|---|
| Операционная система | Linux |
| Python | 3.12 и выше |
| CUDA | 12.8 |
| PyTorch | 2.7.1 |
| GPU | NVIDIA H100 80 ГБ (рекомендовано) |
| Дисковое пространство | ~6 ГБ |
Рекомендуемый GPU — NVIDIA H100 с 80 ГБ видеопамяти. Такая конфигурация обеспечивает обработку крупных наборов данных и документов со сложной структурой без заметных задержек. В тестовых сценариях с менее производительными GPU возможна работа модели, однако пропускная способность и скорость обработки будут ограничены.
Для специалистов, занимающихся подбором серверной инфраструктуры под задачи с HunyuanOCR, СервакМастер предлагает широкий выбор GPU-серверов и рабочих станций на базе NVIDIA. Свяжитесь с нами для консультации по оптимальной конфигурации.
Архитектурный пайплайн HunyuanOCR
Пайплайн ИИ-модели HunyuanOCR реализует сквозную обработку: входное изображение поступает напрямую в мультимодальный энкодер, который совместно обрабатывает визуальные и текстовые признаки. Далее декодер на основе трансформерной архитектуры генерирует структурированный ответ согласно инструкции пользователя. Отсутствие промежуточных каскадов сокращает накопление ошибок и повышает итоговую точность.
Источник архитектурной схемы: официальный репозиторий Tencent на GitHub.
Выводы
HunyuanOCR занимает сильную позицию на рынке мультимодальных OCR-решений, предлагая редкое сочетание доступности, универсальности и производительности. Компактность модели (1 млрд параметров) не идёт в ущерб качеству: благодаря продуманной архитектуре и сквозному подходу к обработке документов, HunyuanOCR превосходит более крупных конкурентов на ключевых бенчмарках.
Широкие языковые возможности (100+ языков), поддержка сложных структурных форматов и относительно низкие требования к дисковому пространству (~6 ГБ) делают модель привлекательным выбором для компаний, выстраивающих масштабируемые документальные пайплайны. Главное ограничение — необходимость в мощном GPU уровня NVIDIA H100 для достижения оптимальной производительности. Именно здесь СервакМастер готов помочь: подобрать, поставить и настроить серверное оборудование под конкретные рабочие нагрузки.
Материал подготовлен редакцией СервакМастер.