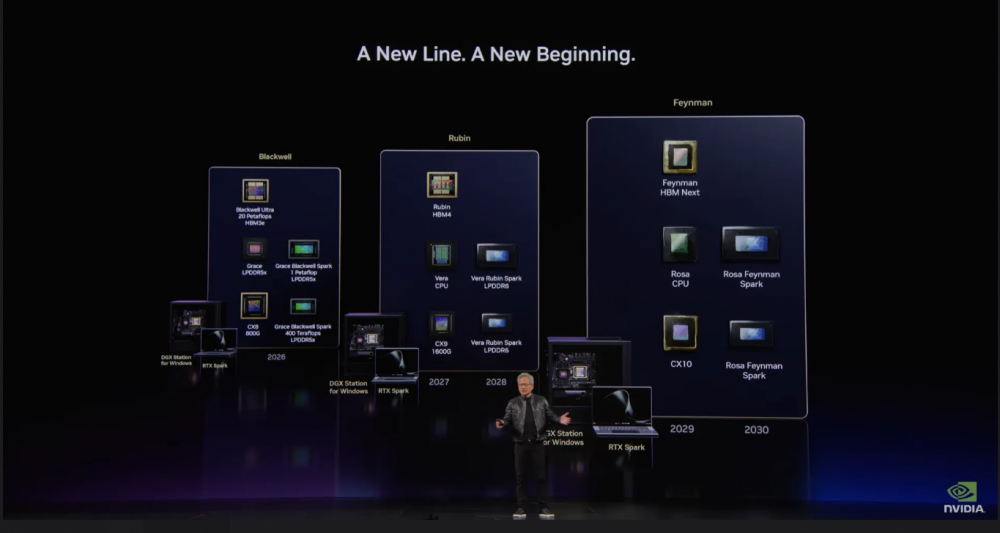
NVIDIA раскрыла дорожную карту RTX Spark: платформы Vera Rubin с LPDDR6 и Rosa Feynman изменят рынок ИИ-ПК
~ 2 мин
Введение
На выставке Computex 2026 генеральный директор NVIDIA Дженсен Хуанг не ограничился анонсом первого поколения платформы RTX Spark — он публично зафиксировал долгосрочные обязательства компании по развитию решений для локальных ИИ-сценариев на Windows on ARM. Это важный сигнал для рынка: NVIDIA рассматривает потребительские Arm-системы как стратегическое направление, а не единичный эксперимент.
Первым на прилавки поступит семейство Grace Blackwell Spark к концу 2026 года. Вслед за ним последуют два новых поколения: на архитектуре Vera Rubin с памятью LPDDR6 и на базе Rosa Feynman с ещё более скоростной памятью — предположительно LPDDR6X.
Подробнее о дорожной карте RTX Spark
Первое поколение — Grace Blackwell Spark
Стартовая платформа уже хорошо изучена. RTX Spark Superchip включает:
- 20-ядерный процессор Grace на архитектуре Arm
- Графику Blackwell RTX 5070
- До 128 ГБ унифицированной памяти LPDDR5X
- Пропускная способность памяти — 600 ГБ/с
- Техпроцесс — 3 нм
Это монолитный чип с унифицированной памятью, где CPU и GPU делят единый пул ОЗУ без узких мест шины PCIe.
Второе поколение — Vera Rubin
Хуанг особо подчеркнул, что каждое следующее поколение RTX Spark получит принципиально новый кристалл. Платформа Vera Rubin принесёт:
- Переход на стандарт LPDDR6 — более высокая пропускная способность по сравнению с LPDDR5X
- Улучшенную GPU-архитектуру на базе Rubin
- Вероятный переход на 2-нм техпроцесс вместо текущих 3 нм — итоговая экономия энергии и рост производительности на ватт
Третье поколение — Rosa Feynman
Завершает трёхступенчатую дорожную карту чип семейства Rosa Feynman:
- Новый тип памяти — предположительно LPDDR6X с ещё большей пропускной способностью
- Следующий шаг архитектуры GPU
- Дальнейшее развитие поддержки Windows on ARM
Ни точных дат, ни полных спецификаций NVIDIA пока не раскрыла, однако сам факт публичного анонса трёхпоколенной дорожной карты — это недвусмысленный сигнал партнёрам и покупателям: платформа будет поддерживаться долгосрочно.
Почему NVIDIA в выигрышном положении
На брифинге представители компании сделали акцент на уникальном программном стеке CUDA. В отличие от предыдущих попыток других игроков создать жизнеспособную альтернативу x86 на Arm, у NVIDIA есть:
- CUDA — зрелая экосистема с тысячами библиотек и инструментов
- Оптимизированные открытые модели под аппаратное обеспечение NVIDIA
- Перенос облачного стека в клиентские устройства без переписывания кода
Это выгодно отличает RTX Spark от решений Apple и AMD: обе компании предлагают мощное железо, однако инфраструктура разработки и развёртывания ИИ-моделей у них значительно скромнее. Разработчики, уже использующие CUDA в дата-центрах, смогут запускать те же рабочие нагрузки на настольном RTX Spark без изменений в коде.
DGX Station: та же архитектура для рабочих станций
Параллельно с массовыми чипами Spark NVIDIA развивает высокопроизводительные рабочие станции DGX Station на Windows Arm. Флагманская модель на суперчипе GB300 уже включает:
- 72-ядерный процессор Grace
- 496 ГБ унифицированной памяти LPDDR5X
- GPU Blackwell Ultra с 252 ГБ HBM3E
Это означает единую архитектурную линию от тонкого ноутбука до настольного суперкомпьютера для ИИ-разработчиков. Один и тот же CUDA-код, одни и те же модели, одно и то же программное окружение — только масштаб разный.
Что это означает для покупателей и партнёров
Публичная трёхпоколенная дорожная карта снимает главный риск ранних вложений: никто не хочет инвестировать в платформу, которую через год забросят. Для корпоративных покупателей и разработчиков это важный сигнал:
- Платформенная преемственность — приложения и модели, написанные под Grace Blackwell Spark, будут работать на Vera Rubin и Rosa Feynman
- Постепенное нарастание производительности — каждое поколение приносит более быструю память и более экономичный техпроцесс
- Единый стек разработки — CUDA, TensorRT, NIM-микросервисы одинаково работают на всех поколениях
Выводы
Дорожная карта RTX Spark показывает: NVIDIA целенаправленно строит замену классической связке x86-процессор плюс дискретный GPU. Монолитные Arm-чипы с унифицированной памятью — Grace Blackwell сегодня, Vera Rubin завтра, Rosa Feynman послезавтра — последовательно закрывают сценарии локального ИИ-инференса для широкого круга устройств.
Ключевое преимущество NVIDIA здесь не только в кремнии, но и в программном стеке: именно CUDA-экосистема делает переход на Arm-платформу менее болезненным для разработчиков и корпоративных клиентов.
Следите за новостями на СервакМастер — мы публикуем актуальные обзоры серверного и ИИ-оборудования и готовы помочь подобрать решение под ваши задачи. Свяжитесь с нами для консультации.