Curiosity-driven Exploration: революционный метод обучения языковых моделей с подкреплением
Введение
Группа учёных — Руньпэн Дай, Линьфэн Сун и Хаолин Лю — представила систему Curiosity-Driven Exploration, которая встраивает механизм «любопытства» непосредственно в процесс обучения ИИ-моделей. Главная цель разработки — улучшить принятие решений и предотвратить явление энтропийного коллапса, при котором языковая модель со временем начинает генерировать однообразные, шаблонные ответы.
Новый метод представляет собой значительный шаг вперёд в области обучения с подкреплением (Reinforcement Learning) для больших языковых моделей (LLM). В редакции СервакМастер разбираем, как именно работает эта технология и почему она важна для всей отрасли.
Что такое Curiosity-Driven Exploration и как он работает
Традиционные подходы к обучению LLM нередко сталкиваются с серьёзной проблемой: модель исследует обучающие данные неэффективно, что ведёт к предсказуемым и ограниченным ответам. Со временем мыслительные способности модели перестают развиваться — наступает так называемый энтропийный коллапс.
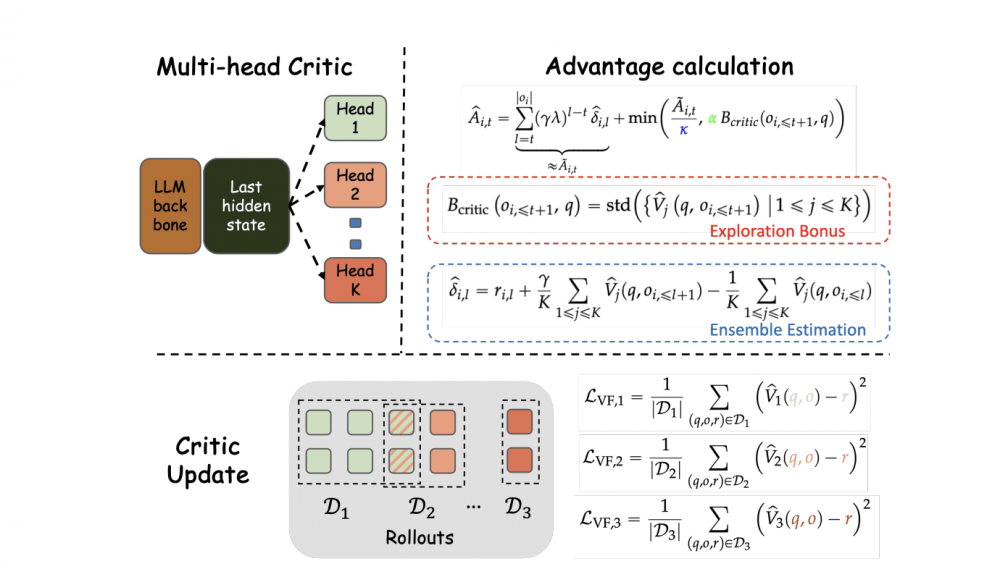
Curiosity-Driven Exploration решает эту проблему принципиально иначе. Метод реализует принцип «любопытства» через два независимых канала сигналов:
- Бонус агента — формируется на основе генерации ответов и побуждает модель пробовать разнообразные варианты, снижая чрезмерную самоуверенность при выводе текста.
- Бонус критика — формируется на основе оценки результатов и направляет агента к эффективным стратегиям исследования данных, согласуясь с лучшими практиками в этой области.
Оба сигнала вместе создают исследовательский бонус, который поощряет модель за точные и при этом разнообразные ответы, не позволяя ей «застрять» в одной и той же колее.
Техническая основа метода
В основе методологии лежат два ключевых инструмента:
- Линейные марковские процессы принятия решений (MDP) — формализуют задачу обучения как последовательность состояний и переходов, что позволяет точно моделировать долгосрочные последствия каждого генерируемого токена.
- Multi-head критики — система из множества оценщиков стоимости, работающих параллельно. Применение бутстрэппинга в сочетании с несколькими оценщиками позволяет значительно точнее вычислять исследовательский бонус, чем при использовании одного критика.
Такая архитектура даёт модели возможность оценивать не только немедленный результат генерации, но и перспективу всей цепочки рассуждений — что особенно ценно для задач, требующих многошагового вывода.
Экспериментальные результаты
Исследователи проверили метод на одном из наиболее авторитетных бенчмарков для оценки математического мышления — AIME (American Invitational Mathematics Examination). Результаты оказались впечатляющими:
- Производительность модели выросла примерно на три балла в сложных задачах на математическое мышление.
- Детальный анализ показал, что бонус агента эффективно снижает чрезмерную самоуверенность модели при выводе ответов.
- Бонус критика подтвердил соответствие передовым методам исследования данных и помог выявить оптимальные стратегии обучения.
Таким образом, Curiosity-Driven Exploration не просто теоретическая концепция, а практически верифицированный инструмент повышения качества LLM.
Проблема калибровки и галлюцинации в LLM
Помимо улучшения математических способностей, исследование выявило фундаментальную проблему, которая давно беспокоит разработчиков ИИ: нарушение калибровки моделей при стандартном обучении с подкреплением.
Когда модель систематически «переоценивает» своё знание, возникают галлюцинации — уверенные, но ошибочные ответы. Авторы работы показали, что это напрямую связано с энтропийным коллапсом: чем однообразнее ответы модели, тем выше вероятность, что она выберет «привычный», но неверный путь рассуждений.
Перспективным решением учёные называют альтернативные системы вознаграждения, в частности бонус на основе перплексии (perplexity-based bonus). Его использование позволяет существенно повысить эффективность обучения и уменьшить количество галлюцинаций, поскольку модель получает явный стимул к поиску нестандартных и корректных формулировок.
Значение для будущего искусственного интеллекта
Curiosity-Driven Exploration открывает несколько важных направлений для дальнейшего развития ИИ:
- Более надёжные рассуждения. Модели, обученные с использованием механизма «любопытства», демонстрируют устойчивость даже в условиях неопределённости — они не «зацикливаются» на одном подходе, а исследуют альтернативы.
- Снижение риска галлюцинаций. Правильная калибровка уверенности модели напрямую влияет на достоверность её ответов в реальных задачах.
- Применимость в сложных доменах. Математика — лишь один из примеров. Метод потенциально применим в программировании, логике, научных вычислениях и других областях, где требуется многошаговое мышление.
- Масштабируемость. Архитектура multi-head критиков хорошо масштабируется: добавление новых оценщиков позволяет адаптировать метод к задачам разной сложности без кардинальной перестройки всей системы обучения.
Выводы
Подход Curiosity-Driven Exploration — это не просто очередная оптимизация гиперпараметров, а концептуально новый взгляд на то, как должна работать система обучения с подкреплением для LLM. Встраивая «любопытство» в сам алгоритм, исследователи добиваются того, что модель перестаёт «идти по накатанной» и начинает по-настоящему исследовать пространство возможных ответов.
Команда СервакМастер следит за развитием технологий искусственного интеллекта и готова помочь с подбором серверного оборудования для любых вычислительных задач — от инференса LLM до обучения нейронных сетей. Если вам нужна консультация по выбору серверов или GPU-ускорителей — свяжитесь с нами.
Автор: редакция СервакМастер